Blocksteady has been an Indexer on The Graph from the outset with the launch of mainnet and has been committed to operating a reliable Indexer that made the most efficient use of our Delegators’ stake.
Stake management
Our process of managing allocated stake utilises a data store which highlights imbalances between curation signal and stake allocation to find ‘gaps’ to fill. These opportunities provided the best rate of GRT/hour for our Delegators. However, since the advent of AllocationOpt from the GraphOps team, this process has been greatly improved. We still maintain our data store as it has now been re-appropriated as input for AllocationOpt.
We run this tool regularly to identify whether our current allocations differ significantly from the recommendations provided and, if so, it will shuffle the subgraphs we are indexing. The resulting impact is a boost in GRT/hour immediately following the allocations which will naturally decline as we lose our ‘edge’ to Indexers that are following to fill the gaps between signal and allocated stake. At this time we will update our data store with newly added subgraphs and then re-run the AllocationOpt tool to find new opportunities.
Example analysis from the AllocationOpt tool:
Serving Data
While Indexers on The Graph are predominantly incentivised via indexing rewards, Blocksteady has not lost sight of the bigger picture and is aiming to deliver queries in volume and in a cost-effective manner for consumers. We monitor subgraphs that are serving significant query volume and provide input to the AllocationOpt tool to ensure we are indexing on these subgraphs when we go about re-allocation.
Additionally, we have integrated AutoAgora from Semiotic Labs and its associated components to our indexing stack so that queries are ingested, analysed, and cost models set in an automated fashion. This ensures we remain ultra-competitive when serving queries on the subgraphs we are indexing, attempting to maximise volume while providing queries at a competitive rate.
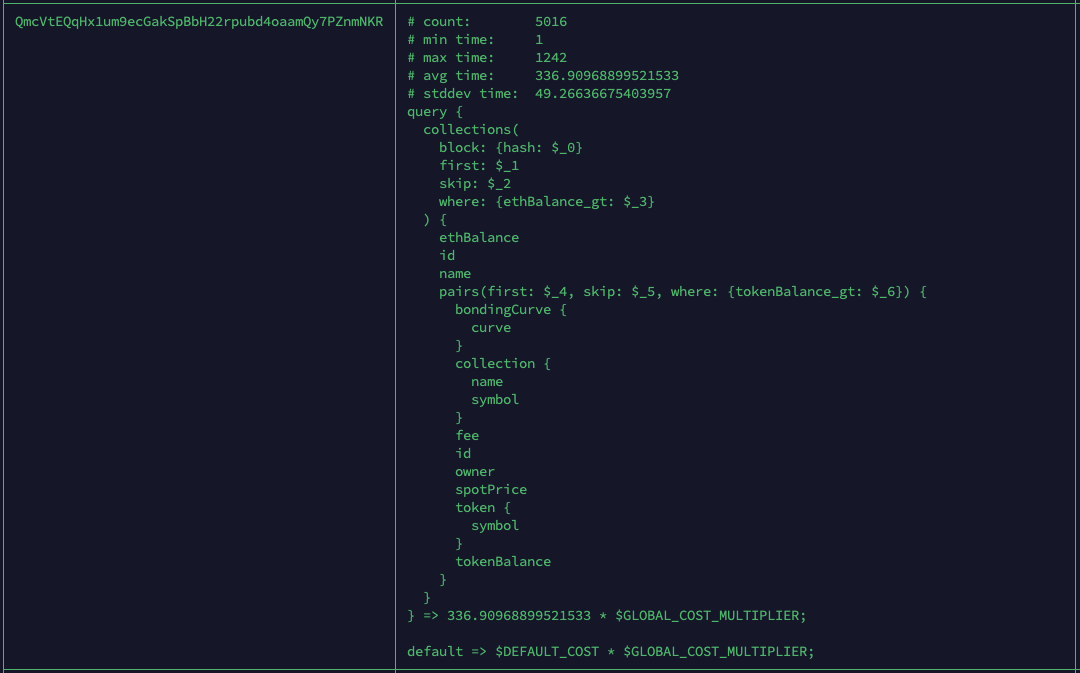
As you can see in the example below, queries are analysed for ‘archetypes’ which form the basis of costing according to complexity, all of which is handled automatically by AutoAgora. The result of implementing AutoAgora was a significant increase in queries served, and a lot less manual effort and guesswork when it came to setting cost models by hand in the past.
Sample query ‘skeleton’ with calculated cost set by AutoAgora:
Looking forward
Blocksteady is excited for where the next steps take us for indexing data within web3, and is participating within the Migration Infrastructure Providers (MIPs) program to expand its capabilities beyond Ethereum data availability to chains such as Gnosis and beyond.
We hope you enjoyed reading this article about how Blocksteady has leaned into the fantastic tools developed by Semiotic Labs and GraphOps to provide an optimal service to both our Delegators and data consumers, and would welcome your delegation if you feel it will be well utilised. If you have any questions for us at all feel free to drop into our telegram chat (link below).
We are particularly excited to welcome Delegators who have an interest in Curation on the network, as we believe that the relationship between an attentive Indexer and Curators can be very mutually beneficial. I am always happy to feed back to Curators observations on query traffic on recently deployed subgraphs so that they may adjust their signal accordingly.
To learn more about myself and the journey as an Indexer on The Graph I have been interviewed on GRTiQ episode #60, which can be found in your podcast player or at the GRTiQ website.
You can also find us at:
https://twitter.com/Blocksteady3/
https://thegraph.com/explorer/profile/0xf3f182e859f789af8d6c2223d15c691471c79a2b